Jiali Duan is currently a master student at Univeristy of Chinese Academy of Sciences



Appear in CCBR 2016 (Best Student Paper)
Face detection evaluation generally involves three steps: block generation, face classification, and post-processing (Motivation). However, firstly, face detection performance is largely influenced by block generation and post- processing, concealing the performance of face classification core mod- ule. Secondly, implementing and optimizing all the three steps results in a very heavy work, which is a big barrier for researchers who only cares about classification. Motivated by this, we conduct a specialized benchmark study in this paper, which focuses purely on face classifica- tion. We start with face proposals, and build a benchmark dataset with about 3.5 million patches for two-class face/non-face classification. Re- sults with several baseline algorithms show that, without the help of post-processing, the performance of face classification itself is still not very satisfactory, even with a powerful CNN method.
The data and evaluation code of this study will be released to the public to help assess performance of face classification, and ease the participation of related researchers who want to try their algorithms for face detection. With this benchmark, researchers only need to do feature extraction and face classification per image patch, regardless the troubling block generation and post-processing tasks. Even more easily, we provide some baseline features, so that general clas- sification researchers are able to evaluate their classification algorithms.








@inproceedings{face_classification,
title={Face Classification: A Specialized Benchmark Study},
author={Jiali Duan, Shengcai Liao, Shuai Zhou, and Stan Z. Li},
conference={ccbr},
year={2016}
}
RPN network is employed to extract proposals inspired by the work of Faster R-CNN and its recent application in face detection. Note that generic object proposal-generating methods are not very suitable for our classification benchmark because the amount of positive face patches generated is too scarce and those patches are not as discriminative as a specially trained RPN face proposal network.
We trained a 4-anchor RPN network with some slight modifications on the fc6 and fc7 InnerProduct layer of Zeiler and Fergus model. The default anchor ratio was set to 1:1 and we compute anchors at 4 different scales (2,8,16,32). Dur- ing training, the number of categories are modified to 2 (face and background) with 2*4 bounding box coordinates to be predicted. Softmax and smoothL1 loss are deployed for training classification and bounding box prediction respectively.
The performance of RPN is evaluated on AFW database, through ROC curve.
All the proposals are generated from the training set of WIDER FACE containing 12,880 high-resolution images through this RPN convolutional neural network. There are about 300 proposals extracted from each image. WIDER FACE contains 393,703 labelled faces collected from 32,203 images with a wide variety in scales, poses, occlusions and expressions. As shown in Table 1, proposals are extracted from the first 6,440 images in WIDER FACE are used as the training set, while the remaining proposals from the next 6,440 images are used as testing set. In the testing set the size of Non- face patches are about 20 times the size of face proposals.
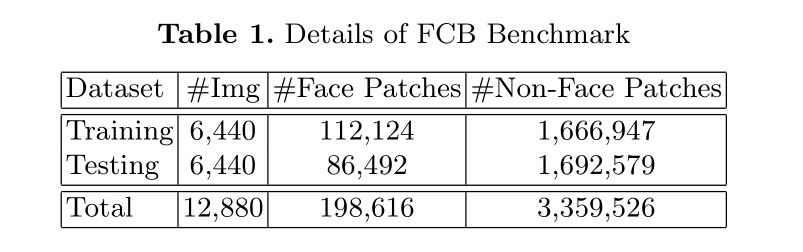
In our benchmark dataset, when the Intersection over Union (IOU) between a face proposal generated by RPN and a ground-truth label is greater than 0.5, we treat it as a face patch. Otherwise, when the IOU is below 0.3, we treat it as a non-face patch. As a result, we collected a face classification benchmark (FCB) database, which contains 3,558,142 proposals in total, of which 198,616 being face patches. All images are resized to 24x24 for face classification benchmark. Note that by doing so there may be some changes to the original aspect ratio.
Below are some sample patches of the proposed face classification benchmark.

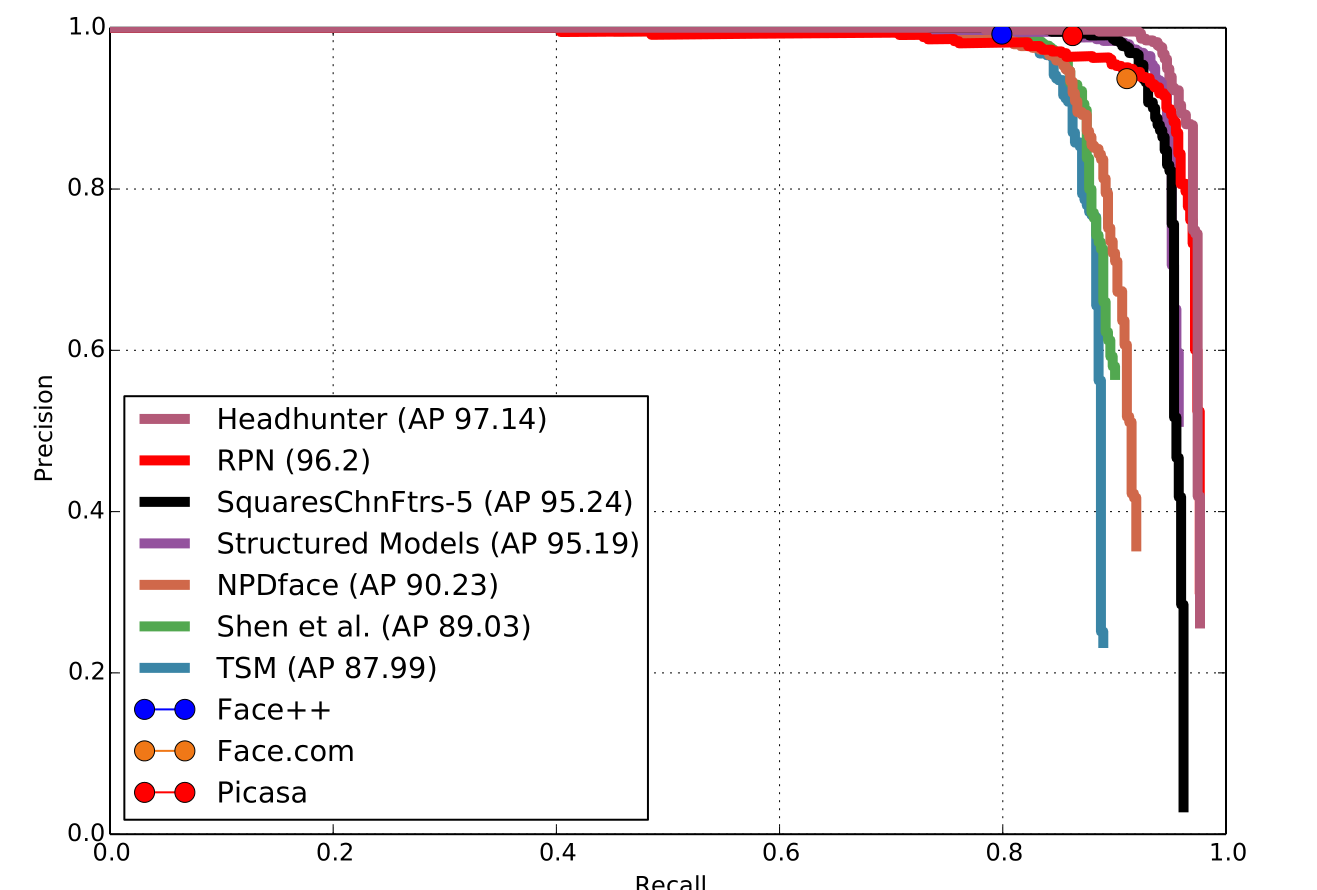
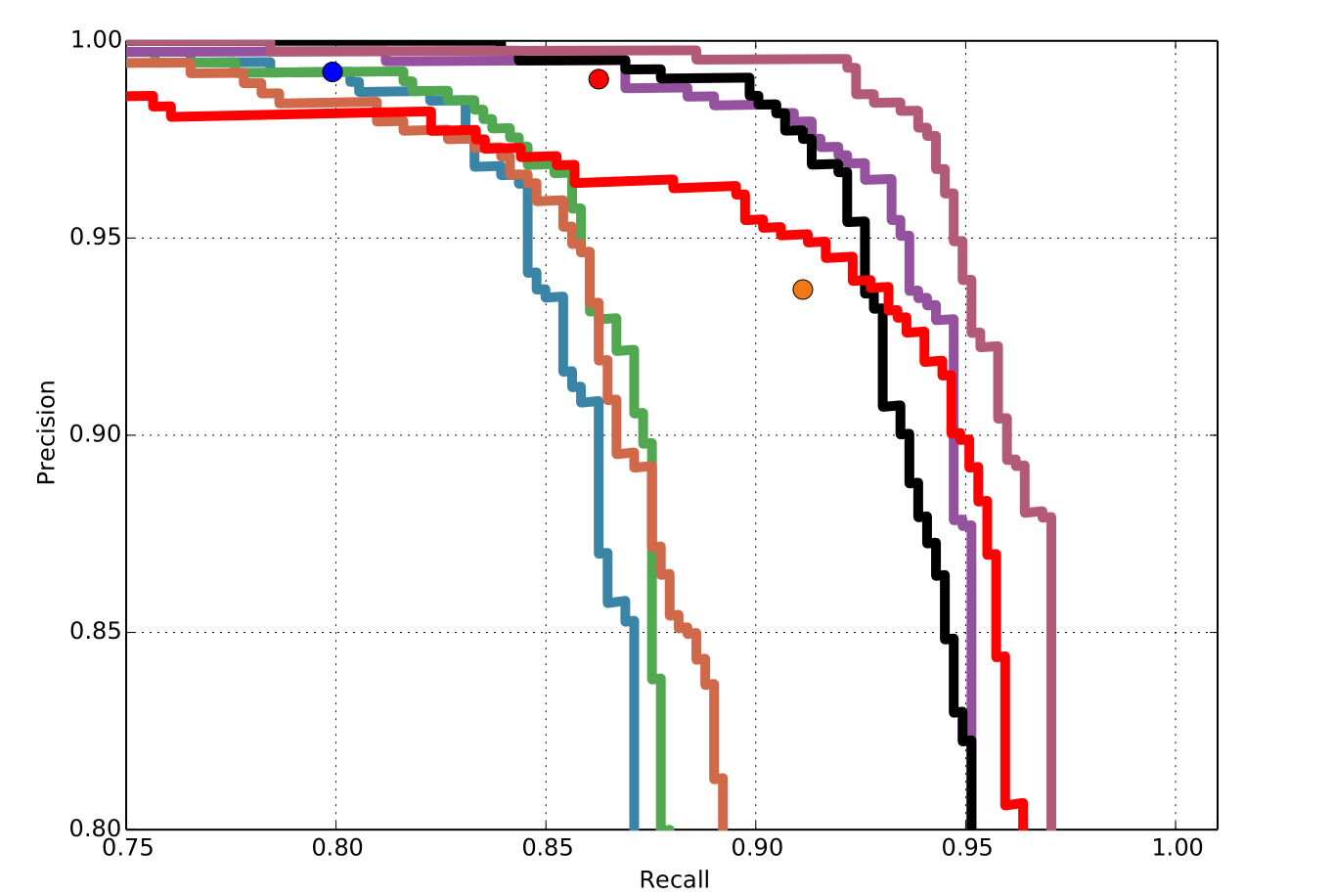
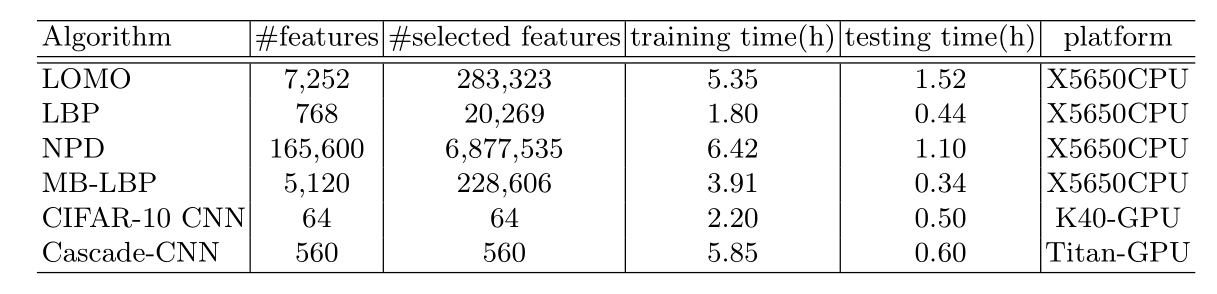
Traditional Methods: Illumination changes, occlusions and pose variation- s are three fundamental problems for face detection under unconstrained set- tings. Illumination-invariance is obtained in LOMO by applying the Retinex transform and the Scale Invariant Local Ternary Pattern (SILTP) for feature representation. NPD gives the nice properties of scale-invariance, bounded- ness and its feature involves only two pixel values, hence robust to occlusion and blur or low image resolution. We use the open source code of these two feature representation methods in our experiments. Besides, LBP together with its variant MB-LBP are also re-implemented for evaluation. We adopt DQT+boosting as our baseline classifier. We also tried SVM, but it appears to be not effective to handle this challenging problem, and it is also not efficient for our large-scale data. Therefore, we leaved SVM out finally.
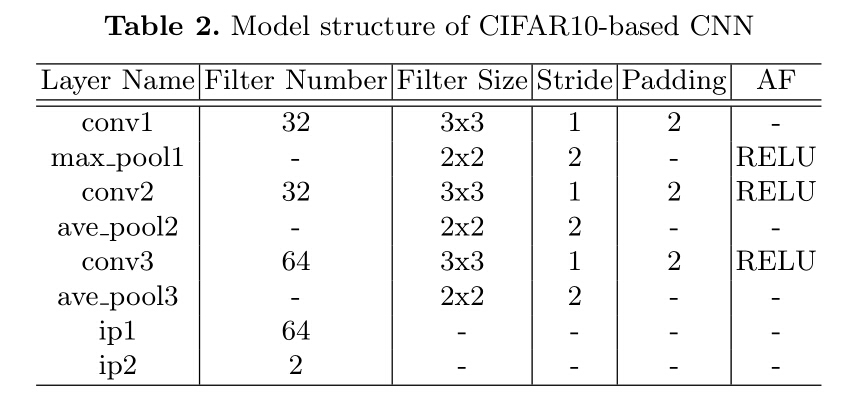
CNN Methods: Convolutional Neural Network based methods have re- ceived more and more attention due to its effectiveness in computer vision tasks. In our experiments, a CIFAR-10 Net based binary classification CNN and a Cascade-CNN following the paradigm of have been implemented. Several CNN structures have been explored and we picked one with the best performance based on CIFAR-10 and its detailed information is listed in Table 2. As for the structure of Cascade-CNN. Note that for training Cascade-CNN, hard negative samples mined by the former net are used as non- face samples to be used for the following net training and in training each net, hard positive samples mined are aggregated to face proposals for further fine- tuning.
Traditional methods as well as CNN methods mentioned above have been tested on our benchmark, below shows the evaluation ROC figure, model details and speed of corresponding algorithms.
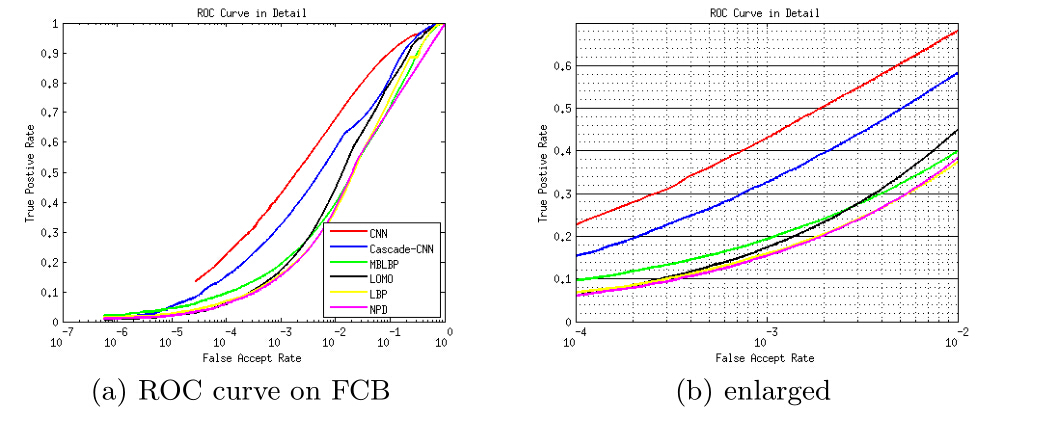
Face detection generally involves three steps with face classification being its core module. However, it is not easy to determine the actual performance of the face classification part due to the large influence of block generation and post- processing in traditional benchmarks. Motivated by this, we conduct a special- ized benchmark study in this paper, which focuses purely on face classification. We start with face proposals by collecting about 3.5 millions of face and non-face sample patches, and build a benchmark dataset (FCB) for two-class face classi- fication evaluation. Our results show that, without the help of post-processing, the performance of face classification itself is still not very satisfactory, even with a powerful CNN method. The data and evaluation code of this study will be re- leased to the public to help assess performance of face classification, and ease the participation of other related researchers who want to try their algorithms for face detection.